Project Introduction
Laryngeal bioimpedance can deliver unique information about human voice and phonation.
This project has two main aspects:
- Development of a self-calibrating laryngeal bioimpedance measurement system
- Application of this system for voice features extraction and classification
We employ Artificial Neural Networks for near real-time classification of voice acts, distinguishing between speech and singing.
One of the project’s key contributions is the creation of a unique dataset of laryngeal bioimpedance measurements, enabling training of AI models. This technology aims to support:
- Voice disorder evaluation and pre-diagnosis
- Broader applications in phonation-driven systems
Dataset
A laryngeal bioimpedance measurement system developed by the team was used to record voice acts from multiple participants.
The dataset includes:
- Speaking voices
- Singing voices

A dataset created with laryngeal bioimpedance measurements
Network Architecture
For processing the data, Mel Frequency Cepstrum Coefficients (MFCC) were extracted, producing frequency coefficients over 20 frequency bands.
These coefficients formed the input features for the neural network.
Architecture
- Input Layer: 20 neurons
- Hidden Layer: 40 neurons
- Output Layer: 1 neuron (binary classification: speech vs. singing)
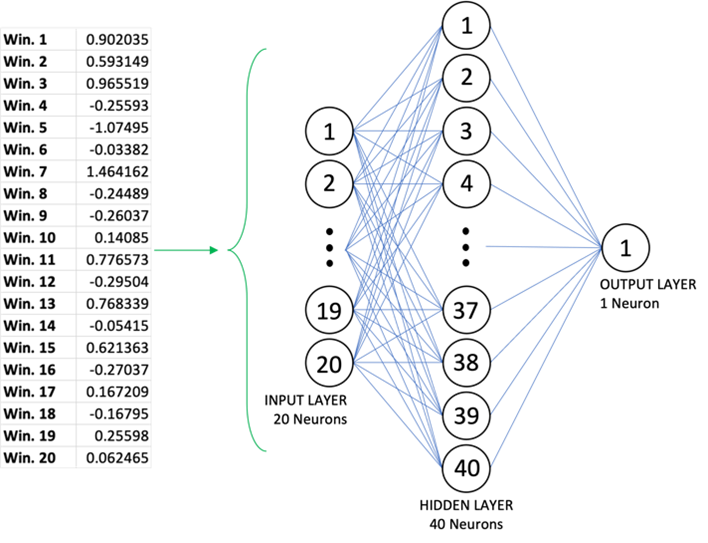
Neural network used for classification
Implementation
The models were implemented in Python using the TensorFlow 2.0 framework.
- Data processed into MFCC features
- Neural network trained for binary classification
- Focus on low-latency, near real-time performance
Performance Assessment
Evaluation of the system shows high accuracy in distinguishing between speech and singing.
- Accuracy improves with the number of hidden neurons
- Best results achieved with 40 hidden neurons
- Confusion matrix confirms strong performance on “unseen” data
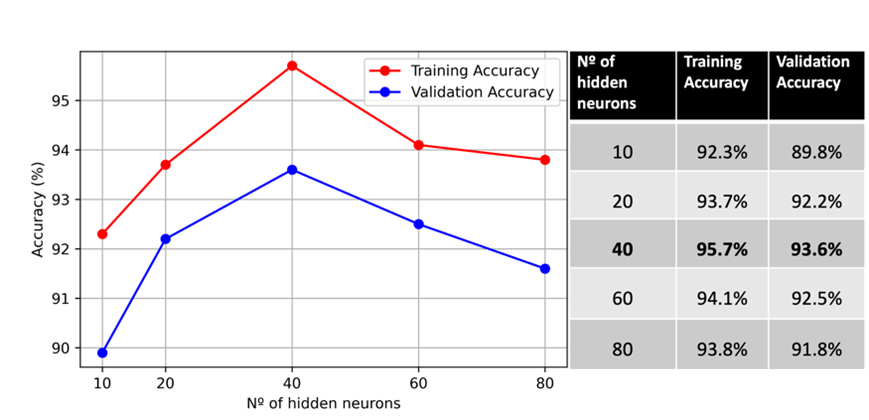
Accuracy comparison by hidden neurons
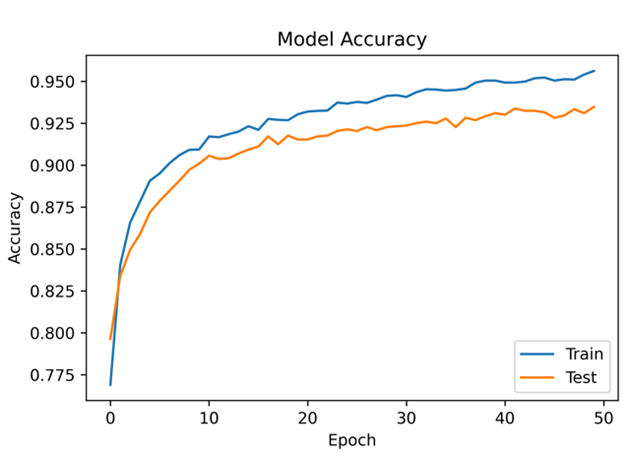
Model accuracy for 40 hidden neurons
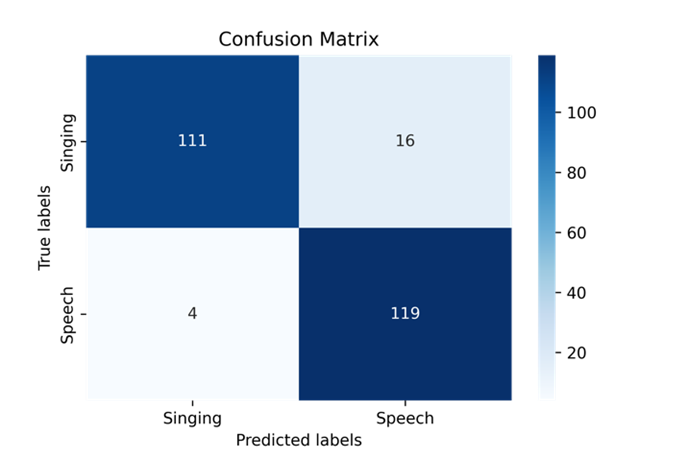
Confusion matrix for unseen data